
🌊 Granola's Growth Playbook: $0 to $1.5B valuation in 3 years
The growth levers, the moat, and the fastest rising AI notepad.

👋 I’m Ivan. I study how top 1% startups grow.

🌊 Granola’s Growth Playbook
Hello there!
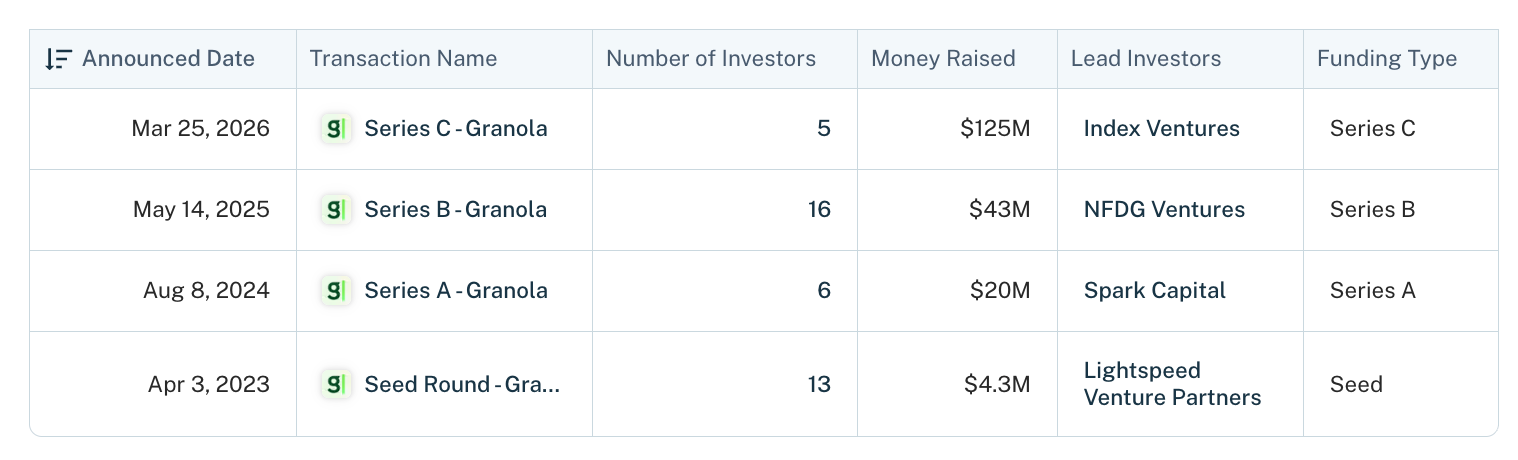
Every operator I know has now heard the story of Granola hitting unicorn status but most have no idea how it actually happened.
Their usage growth and financing rounds speed has made them quite the outlier:
Granola calls itself a “steering wheel for LLMs”. I interpret it as, in a world where ChatGPT and Claude can answer almost any question, their product is the thing that steers those models with the context of what was actually said in your meetings.
Every move in the growth playbook below is basically a brick in that steering wheel.
So I spent the past week pulling apart 10+ founder interviews, every analyst report I could find, and a few profile + metrics floating around the internet.
What you’ll learn in this edition:
The “year in stealth” playbook that cut 50% of features before launch
Why they refused to build a meeting bot when every investor told to
The frontier-model rule that turned a 12.5x cost collapse into a moat
Their “5 Hidden Rules for Building AI Products”
The Recipes launch that turned the angel cap table into a distribution amplifier
The MCP/API/Spaces pivot that turned a notepad into the context layer
And as usual, a few growth lessons for you to steal at the bottom.
Let’s dive in:
📐 Editorial and methodology note: Granola sponsors today’s edition but did not review or approve this Playbook before publication. The Growth Playbook format is mine, I’d write this breakdown whether they sponsored or not. This analysis focuses on the 80/20 mechanics that help explain Granola’s growth (not a comprehensive profile, and not an endorsement or investment advice). Sourced from 18 podcasts and long-form interviews, plus TechCrunch, Bloomberg, Sifted, Sacra, and Granola’s blog. Treat directional estimates as directional.
Act 1: The Wedge (May 2023 → October 2024)
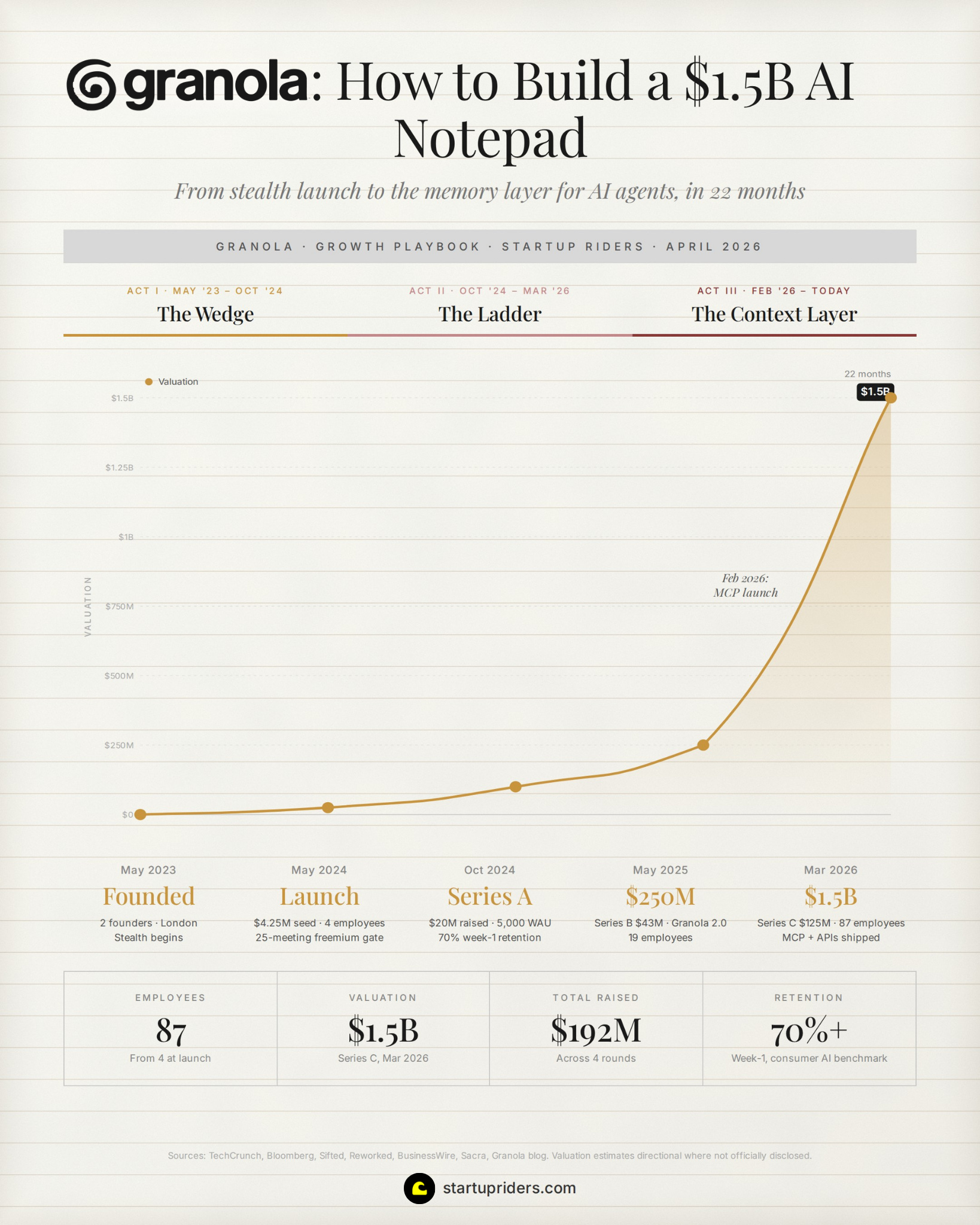
From $0 to 5,000 weekly users.
Chris Pedregal had just sold his last startup, Socratic (ai-powered tutor for high-schoolers), to Google. He quit Google because he wanted to build something on top of GPT-3.
“Within a week of quitting Google I started playing with the instruct version of GPT-3 that had just come out. I was blown away. I was like, okay, this is new. This is different. I don’t know what it is exactly.”
He started looking for a co-founder and stumbled into Sam Stephenson’s profile. Sam was a designer who’d been working on the same idea space from the design side, also based in London, at the note-taking startup Ideaflow. Pedregal sent him a cold email asking to grab a beer and they were off to the races.
They co-founded Granola in March 2023 and within two months they’d closed a $4.25M seed round led by Lightspeed (Mike Mignano was there at the time).
Then they went quiet for a full year.
Growth Lever 1: A stealth year to cut half the product before launch
The stealth year was about increasing feedback loop speed (not secrecy).

Before hitting product-market fit, they were onboarding users manually until they got to about 150 by launch day.
From the MAD Podcast:
“What is the fastest way for me to learn? Will I learn faster if I launch publicly or will I learn faster if I don’t? For about a year, the answer was we’d learn faster if we didn’t launch publicly”
The cost of a public launch in phase 0 is very high because once you have public users, you can’t pivot the core interaction without breaking trust, and they were most likely going to need to pivot.
The first 6 months they built a real-time interaction where you’d type a keyword, hit tab, and Granola would autocomplete the note in real time during a meeting, which made for an incredible demo, they spent 6 months trying to make it work.
Aaand it didn’t.
The notes were good but if a computer is writing notes for you in real time, you can’t help but read them and if you’re reading them. Which kind of went against the whole point of Granola making you more present.
They scrapped the interaction pattern and rebuilt it as a calm text editor that does the magic at the end of the meeting, which was likely a less impressive demo but a way better product.
Pedregal on Invest Like the Best:
“If we had launched that publicly, we never would have been able to switch it. There’s no way. Users would have learned a new behavior. We would have not retained that many users, and that would have been it.”
The stealth year ended with one more move that I think is the single most underrated growth decision they made which was to cut 50% of the features.
One interesting pattern I’m finding in the last few editions analysing growth playbooks of Harvey, Lovable and Perplexity is their willingness to take on hard product trade-offs, almost “courageous”, as long as the iteration cycles were fast enough. I often see startups dying due to a combination of both these factors, hiding behind a false sense of security, not choosing a path with conviction.
“We were in stealth for a year and we kept adding things and adding features and adding views. By the end there was this version of Granola where you could swipe and there were all these panels, your transcript, your notes, your private notes, your notes in another language. It was really like that. We looked at it all and we cut out 50%.”
My take-away here is that the speed at which you can iterate the core interaction is the most valuable asset of an early-stage AI product, because public launches lock you in while stealth can potentially buy you the right to be wrong many times.
Growth Lever 2: Targeting VCs to win the founders behind them
Granola launched publicly on May 22, 2024 with a team of 4 people and a simple pricing of free for the first 25 meetings, and then $10 a month (more on what happened to that price in Lever 5).
Pedregal decided to go after the most specific user persona he could think of, which were venture capitalists. From the MAD Podcast:
“We needed a user type that has a lot of meetings, relatively formulaic, with a relatively formulaic note style, and that we have easy access to. VCs.”
VCs are the smallest market you could pick because they don’t pay much for software, there aren’t that many of them and investors normally see “building for VCs” as a red flag because “the TAM is so small”.
But Pedregal was building for the VC distribution (smart).
Investors are loud on Twitter, talk to founders all day and meet other investors at every dinner. And if a VC starts using Granola, every founder in their portfolio likely sees it, every co-investor sees it and most importantly, VCs were the people Pedregal could get coffee with in London on a week’s notice.
Then, on launch day, he told the team “now we stop building for VCs”.
“As soon as we launched, we said okay great, now we’re done with VCs. We’re going to focus on a different user type. And we chose founders, just because we thought they’d be the hardest. If we could build a great product for founders, then by default it would be a decent product for everyone else.”
VCs were the wedge and founders were the spreaders.
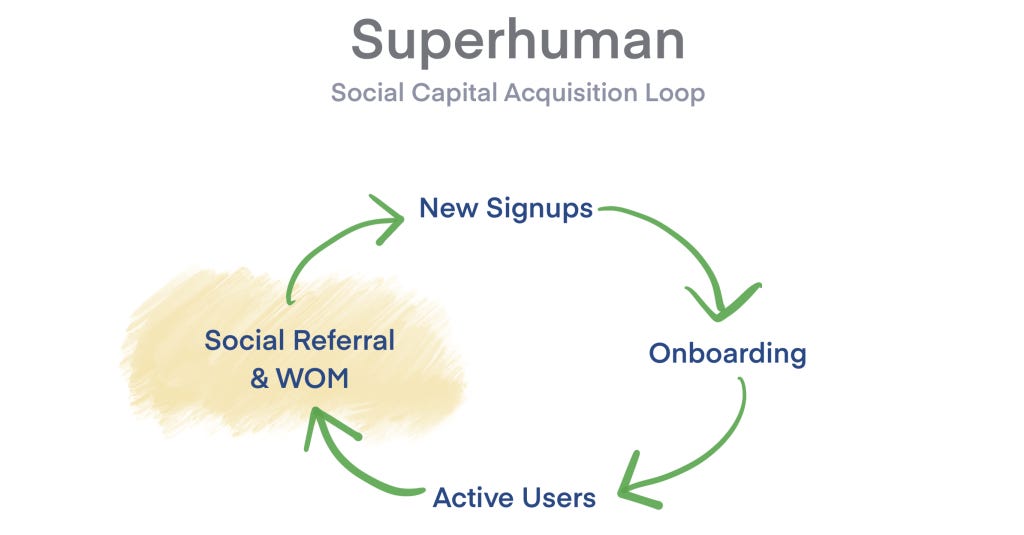
This is similar to the Superhuman strategy and it’s my favorite kind of Trojan horse because you pick the user with the highest signal density per user (not the user with the highest market size per user). If you get them to use it intimately you’ve recruited every person they meet to evangelize on your behalf.
By Series A in October 2024 57% of Granola users were in leadership positions. Which is interesting because Granola didn’t target executives but apparently many of those who were picking up the tool became leaders shortly after.
Growth Lever 3: Refusing the meeting bot to win the meetings that mattered
The AI bot is now a conversation starter for a human to bring up Granola and to vouch for it.

When they launched, every other meeting note-taker in the market joined the call as a visible bot because the bot was their distribution (and it was very annoying).
Granola’s investors told them they were crazy to give that up, but as is usually the case, outlier founders tend to dance to their own beat:
“Bots make you feel kind of weird. A big black box on the screen, sometimes shows up before you’ve joined. But beautiful from a growth distribution standpoint. Every user is exposing everybody they’re meeting with to your product. So everyone thought we were kind of crazy not to do that.”
The cost of the no-bot decision was real and immediate because Granola had no built-in viral loop, no free billboards, no “what’s that bot in the meeting?” recruitment moment and so on.
In return they got something that ended up mattering more which is the right to be in sensitive meetings.
Bots get banned from confidential calls like board meetings, M&A discussions, and executive 1:1s. They usually get rejected by lawyers, doctors, therapists you name it.
So the visible bot maximizes top-of-funnel but minimizes ceiling and they understood that early.
Granola’s experience was to seat on your computer, never announced itself to other participants (someone in a GDPR office right now is having a moment), never recorded audio (transcript only, that decision saved them from many enterprise blockers later), and worked across Zoom, Meet, Teams, Slack Huddles, and in-person calls without any per-platform configuration.
What they discovered is that giving up the viral bot didn’t kill virality but did change the loop:
“If you have a Zoom call and your AI bot shows up, people are now telling each other, ‘Hey, what are you doing with an AI bot? Why aren’t you on Granola yet?”
What’s really cool is that now the competitor’s bot became Granola’s growth loop (this has happened to me, multiple times).
Growth Lever 4: Running frontier models so the moat would be quality
Use the latest, most expensive frontier model. Even when it’s economically unsustainable. Especially when.

In 2023, every meeting note that Granola generated probably cost a few cents in inference, but a heavy user doing 6 meetings a day on the free plan was unprofitable. Which meant every other notetaker in the market used cheaper models or self-hosted to protect margins.
Pedregal told Peter Yang on Behind the Craft why this was actually an advantage:
“AI is different because these models are still expensive to run. Our costs scale linearly with users. This creates an opportunity: as a small startup with fewer users, we can use cutting-edge models that would be financially impossible for big companies to deploy at scale.”
Granola was small enough to run frontier models on every user. But competitors couldn’t, like Otter which likely had $100M ARR and millions of users at the time, couldn’t switch to GPT-4-class models on every transcript without blowing margins.
Then frontier costs collapsed, with the price of transcription alone going from $0.25 per minute in 2021 to $0.02 per minute today, which is a 12.5x cost compression in 5 years, on the single most expensive line in Granola’s stack.
Sam Stephenson on Cognitive Revolution in April 2026:
“There was a time where half of our burn rate as a company was going on transcription. That’s a lot better and more under control now.”
The bet was that running expensive products today is a temporary disadvantage that becomes a permanent advantage. They have apparently been running on frontier-model output since launch, with internal eval tooling that lets the team route across OpenAI, Anthropic, and Google models and swap them overnight without breaking what they call “the Granola voice.”
By the time the costs collapsed users had been trained on a quality of output that nobody else could probably match.
📐 Sidebar: the CEO’s 5 Hidden Rules for Building AI Products
Rule #1: Don’t solve problems that won’t be problems soon: The current wave of AI startups tend to have 2 types of product problems, those the next model release will solve, and those that remain regardless. The mistake tends to be solving the first kind. For example, Granola refused to build chunking for long meetings (context windows expanded), and refused to build multi-language tooling (newer models handled it natively). “As a product person, it goes against every instinct to deny users something they’re actively requesting. But, in AI, sometimes the best strategy is to focus on problems that will still matter even as the tech evolves.”
Rule #2: Go narrow, go deep: “General-purpose tools like Claude and ChatGPT are surprisingly good at many tasks, so if you are building a startup, it needs to solve a problem 10x better. The only way to achieve that is by choosing a narrow use case and making that experience exceptional.” The 10x often comes from non-AI work. For example they built an echo cancellation system for users with and without headphones, which as you can imagine has little to do with note-taking.
Rule #3: Context is king: Pedregal treats the LLM like a smart intern on their first day. The product's job is feeding the intern enough context to figure it out, whereas most AI products out there fail this by writing system prompts that try to anticipate every output.
Rule #4: Your marginal cost is my opportunity: The lever we just discussed above. Frontier models are too expensive for incumbents to deploy at scale, small startups have a temporary cost disadvantage that becomes a permanent quality advantage as costs collapse.
Rule #5: Build products that have a soul. Cohesion comes from intuition, and if you like product as a discipline you’ve probably felt “delight” using Granola. Pedregal does a user call daily and has screens in the office showing real-time feedback, but designs from first principles. “When you’re constantly immersed in user feedback, you develop an emotional sense of what matters rather than just analyzing metrics.”
The numbers at end of Act 1
Half of the people who tried Granola were still active 10 weeks later, doing 6 meetings per week on average.
October 2024: 5,000 weekly active users, a $20M Series A from Spark Capital at undisclosed valuation, which closed in roughly a week after a single day of about 12 investor meetings.
Act 2: The Ladder (October 2024 → March 2026)
By January 2025, Granola was becoming more of a habit than a product with VCs evangelising to founders, founders adopting it for their leadership teams and leadership teams asking for company licenses and so on.
But the AI notetaker market itself was getting brutal (Otter was at $100M ARR, Fireflies hit $1B in a tender offer, Read AI raised $50M, Fathom raised $17M, Plaud was selling AI hardware pendants at $250M annualized, etc etc).
The question shifted from “how do we get users” to “how do we keep them when notes themselves become a commodity?”
Growth Lever 5: Pricing the team plan below the personal plan to force expansion
Each step nudges the exec champion harder toward bringing the company.