Your sales team needs a CRM that runs your entire GTM motion. That’s Attio.
Get agents working on every account, surfacing new opportunities, and handle the work that used to take your team days. Whether you’re working in your browser, inbox, or favorite agent, connect to your customer data in real-time through Attio’s web app, MCP, API, and SDK.
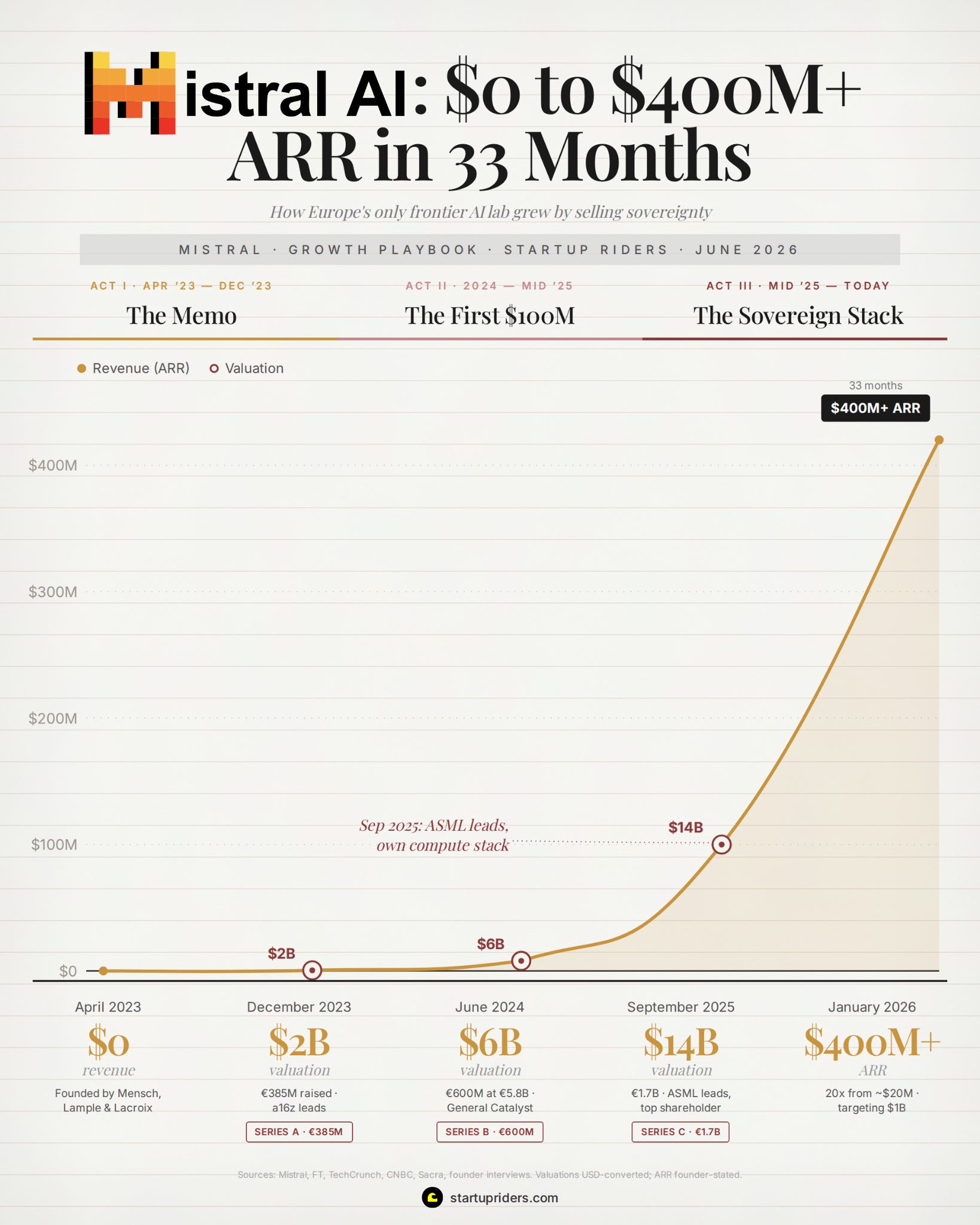
Apparently our french friends at Mistral have achieved an annualized revenue north of $400M in January 2026 (up from $20M a year earlier).
Which is roughly 20x in 12 months…
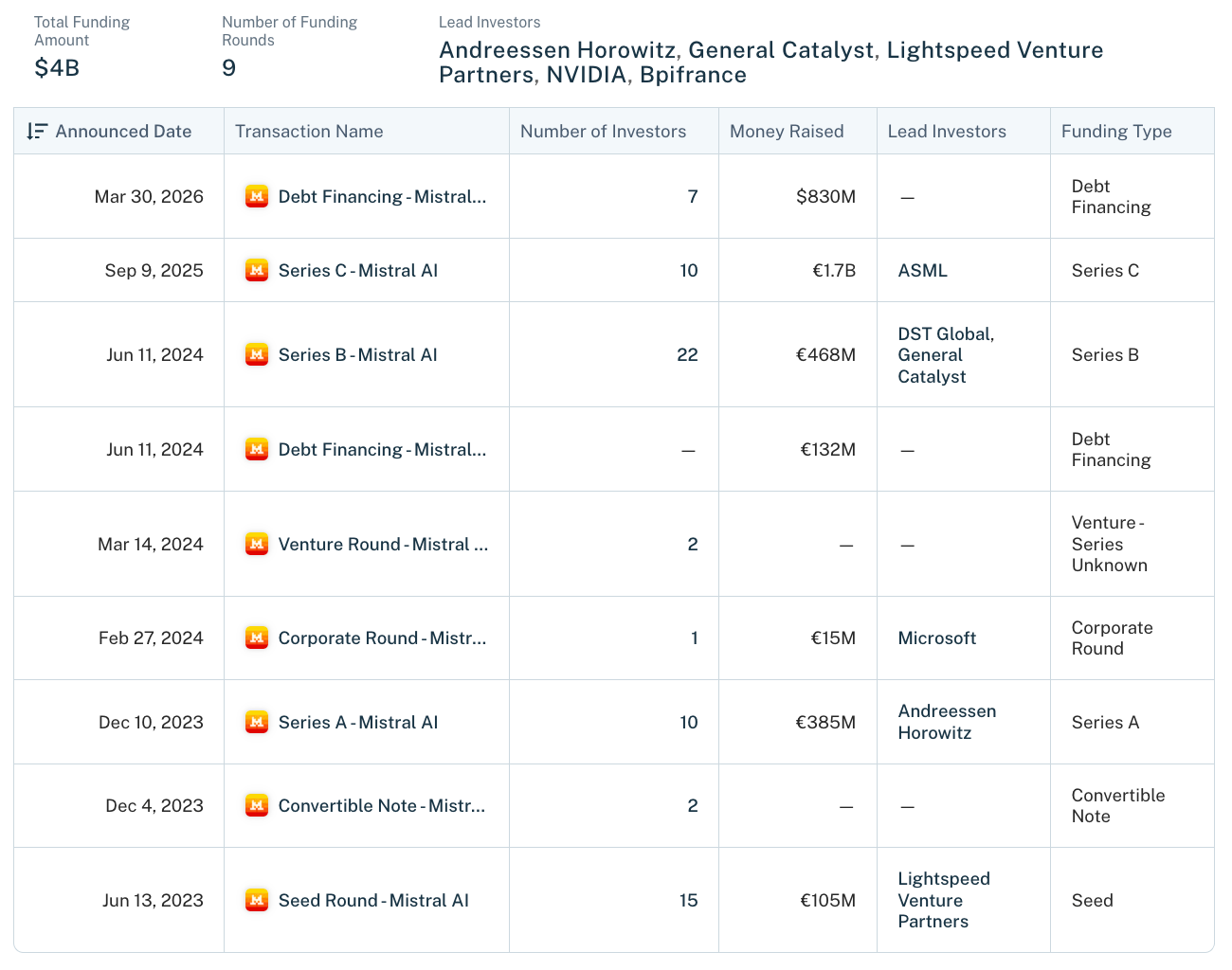
It was founded in Paris in April 2023 and its the only European company building frontier AI anywhere near the level of OpenAI and Google. They’ve also raised a near-$2B Series C at a ~$14B valuation led by ASML, and is targeting more $1B+ in revenue this year, with quite the cap-table:
The most interesting question that came to mind during this analysis is, how do you build something durable when the product you sell might become a commodity (with enormous competitive pressure)?
Which is the exact (contrarian at the time) bet they made from day one. So I spent the past week pulling apart 11 founder interviews, every funding round, and Mistral research I could find.
What you’ll learn:
Why they raised the biggest seed in European history on a 7-page memo
The model they dropped as a bare torrent link at 5am on Twitter
How they took Microsoft’s money and shipped a closed model the same day, then survived the backlash
Why “you don’t want anyone to turn off your systems” became their pitch
How and why they put their own engineers inside their customers
Why a chip-equipment maker led their biggest round
And as usual, a few growth lessons to steal at the bottom.
Let’s dive in:
📐 Quick note on editorial and methodology: this is me surfacing the 80/20 positive anomalies that explain Mistral’s growth (my subjective read, not a comprehensive profile, and not an endorsement or investment advice). It draws on 11 founder interviews and long-form podcasts (a16z, Bloomberg, 20VC, Sequoia, Stripe, etc), plus Mistral’s own posts and reporting from the FT, TechCrunch, CNBC and Sacra. All revenue figures sourced. Reported ARR is a run-rate figure, so treat directional estimates as directional.
The setup for a $400M run
Quick look at the market’s evolution before we dive into growth levers:
Where we come from
From 2020 to 2023 the scarce resource in AI was the handful of people who knew how to train a frontier model. The big dogs (OpenAi etc) turned that scarcity into closed APIs where you sent a prompt to a black box in a US cloud and got an answer back but you never saw the weights and your data sat on their servers.
So the moat was model quality.
Mistral bet on the opposite, with a founding thesis that frontier models commoditize:
“This tech is inherently going to get commoditized. It’s not hard to build. You have around 10 labs in the world that know how to build it, that get access to similar data, that follow the same recipes and algorithms.”
Where we are
The gap between the best open and best closed model shrank from ~6 months in 2024 to ~3 months in 2025. This mainly happened because throwing more raw compute at pre-training stopped working, and every lab now hits the same ceiling in a couple of months. So the labs behind caught up, and the labs ahead ran out of room to pull away.
If the model commoditization assumption holds, then the hundreds of billions going into bigger models might be capex on a depreciating asset:
“Our competitors are investing billions or hundreds of billions into creating assets that are depreciating fairly fast, because those are commodities.”
Mistral’s strategy seems to be a bet that the value won’t sit there, and instead might sit in the 2 things a potential commodity can’t give you:
Being open (so you own and control the thing), not open then closed (wink wink).
Being European (so your data and compute stay in your jurisdiction).
3 dynamics to keep an eye on over the next 24 months:
The gap keeps closing: 6 months, then 3 months, etc so “best model” as a moat keeps eroding, and value keeps sliding downstream to applications, services and infrastructure. This is tends to be good for Mistral’s positioning and bad for anyone whose pitch is “we’re the smartest”. The counter is that “best model” could be the wrong benchmark now because the gap is closing on raw IQ but opening on agentic reliability, distribution, and inference-time compute etc., and those tend to favor the labs with more users and more capital.
Sovereignty becomes a budget (vs a slogan): the founders’ claim is that Europe depends on US providers for the bulk of its digital services, and US decoupling fears turned that into spend. France announced €109B of AI investment around the Paris AI Action Summit, so in a way defense, banking and government now have a reason to buy local that has nothing to do with benchmarks. Then again, the cap table tells a different story which I’m struggling to reconcile... Sovereignty, but funded by a16z, General Catalyst and Microsoft?
Margins compress toward utility economics: the founder says the 70% gross-margin software era is ending and you should run AI “as an infrastructure business.” So this should reshape who wins (aka not the lab with the best demo but the one that owns cheap compute + sticky deployments).
Also, the same logic that helps Mistral can hurt it with (among other threats):
Open weights commoditizingfast cutting both ways (Llama, DeepSeek, Qwen)
Hyperscalersbuildingdown into the sovereign on-prem layer.
The $830M GPU debt only pays off if those GPUs run hot (inference prices fall)
This all started when 3 researchers leave Google DeepMind and Meta and start a company in Paris on 28 April 2023. Arthur (CEO) co-authored DeepMind’s Chinchilla paper on compute-efficient training, Guillaume (chief scientist) and Timothée (CTO) came out of Meta’s FAIR lab and the original LLaMA project.
8 months later they had:
Raised a €105M seed led by Lightspeed at a ~€240M valuation (4 weeks after launch, not bad). largest seed in European history at the time.
Open-sourced Mistral 7B in September as a bare torrent link on X.
Open-sourced Mixtral 8x7B in December, beat Llama 2 70B and GPT-3.5.
Closed a $415M Series A at a $2B valuation, led by Andreessen Horowitz.
The levers they pulled on:
Growth Lever 1: They turned their cap table into their first customers.
“European funds weren’t structured to do the kind of deal we were proposing... they just couldn’t get their head around the investment that needed to be made, whereas we were a pre-revenue company.” — Arthur Mensch, 20VC
Their Series A round had some interesting / unconventional names in it:
BNP Paribas, Europe’s largest bank
CMA CGM, one of the world’s biggest shipping groups
BNP became Mistral’s first paying customer the same year (at ~15 employees) and CMA CGM later signed a €100M, 5-year deal with 6 Mistral staff embedded inside its Marseille HQ (more on this in later). 2 things they did:
The pitch was built for these buyers from week 1: their day 0 memo talked about Mistral as a “European champion with a global vocation” which for a French bank and a shipping group, backing that is almost a form of industrial policy.
They sold before they had a product: months between seed and Series A were spent in enterprise conversations with nothing to sell but prepping the ground.
“We did start the go-to-market motion at the time where we had absolutely nothing to sell. It did create some brand awareness despite the absence of anything.” — Arthur Mensch, 20VC
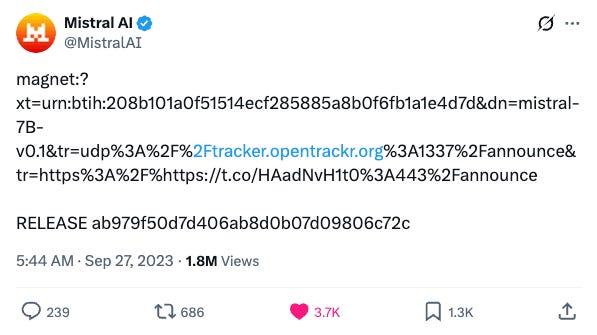
Growth Lever 2: They gave their first model away as a torrent link.
“A shortcut to distribution is to create demand through open source models.”
On 27 September 2023 they shipped its first model (Mistral 7B) as a bare magnet link on a then-inactive Twitter account and it beat Meta’s Llama 2 13B on the benchmarks while being smaller
This looks like a generosity play but it was really a distribution play:
Free distribution: developers who ran it locally became a user with 0 sales cost and the deliberately small size maximised how many machines could run it.
Recruiting magnet: Shipping the best small open model can be a signal flare to the exact engineers you want to hire (worked).
Political goodwill:“European open champion” became an angle (fed Lever 5).
A de facto standard: They repeated it with Mixtral 8x7B in December, which beat Llama 2 70B and GPT-3.5, deliberately the opposite of Google’s heavily-orchestrated Gemini launch.
Growth Lever 3: They bet on efficiency while everyone else bought more chips.
“We have 1.5k H100 which is a few percent of the capacity of our competitors.”
While US labs raised billions to buy bigger and bigger clusters they bet on getting more out of less (remember, Mensch co-wrote Chinchilla, so compute efficiency is in the founding DNA):
“If you look at the way we train models 3 years ago and the way we train models today, I think we have probably made something around 100 times algorithmic improvement. So that’s probably where most of the gains were actually made.”
The efficiency bet shows up in 3 places (and they compound):
Cheaper to train: They started at zero GPUs and trained 7B on about 500 GPUs, shipping it in 4 months, against rivals burning multiples of that. Compute cost also falls ~30% every 2 years on hardware alone, so algorithmic gains stack on top of a falling base.
Cheaper to run: Small specialised models can punch above their size. Their Arabic model M-Saaba (24B) outperforms models 5 times larger. That matters a lot later because cheap-to-run is what makes on-prem and sovereign deployments economically viable.
The most interesting part of this bet is how they reframed their constraint as a strategy, which in turn is what makes the entire downstream business model possible (running it yourself, on-prem, cheaply etc).
ACT 2 — The First $100M
2024 → mid-2025
Act 1 mostly built a brand and a developer base but it did not build a business. Act 2 is how the open-source darling had to do the uncomfortable thing and pick a way to make money (+ take the heat for it):