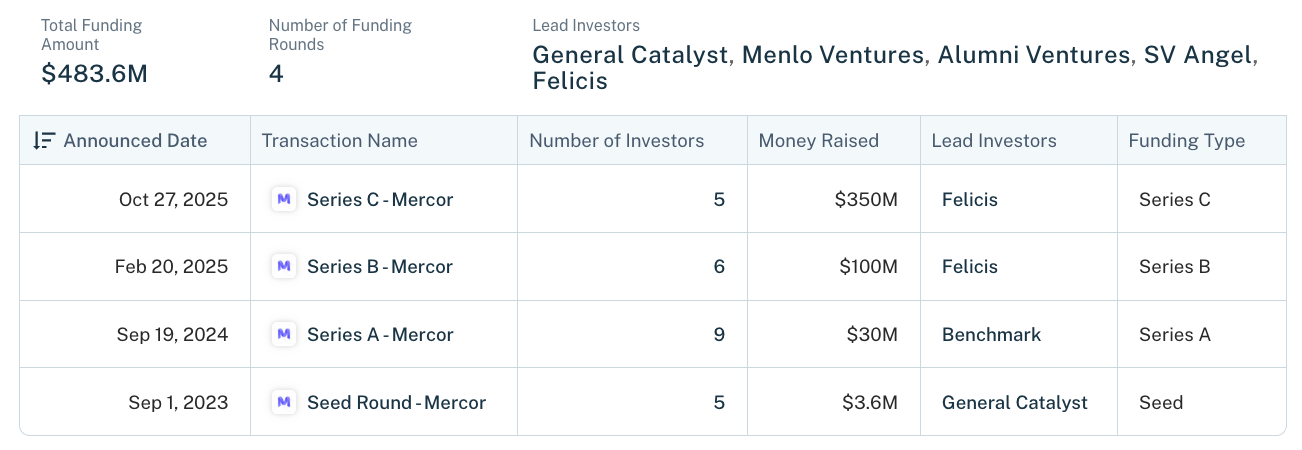
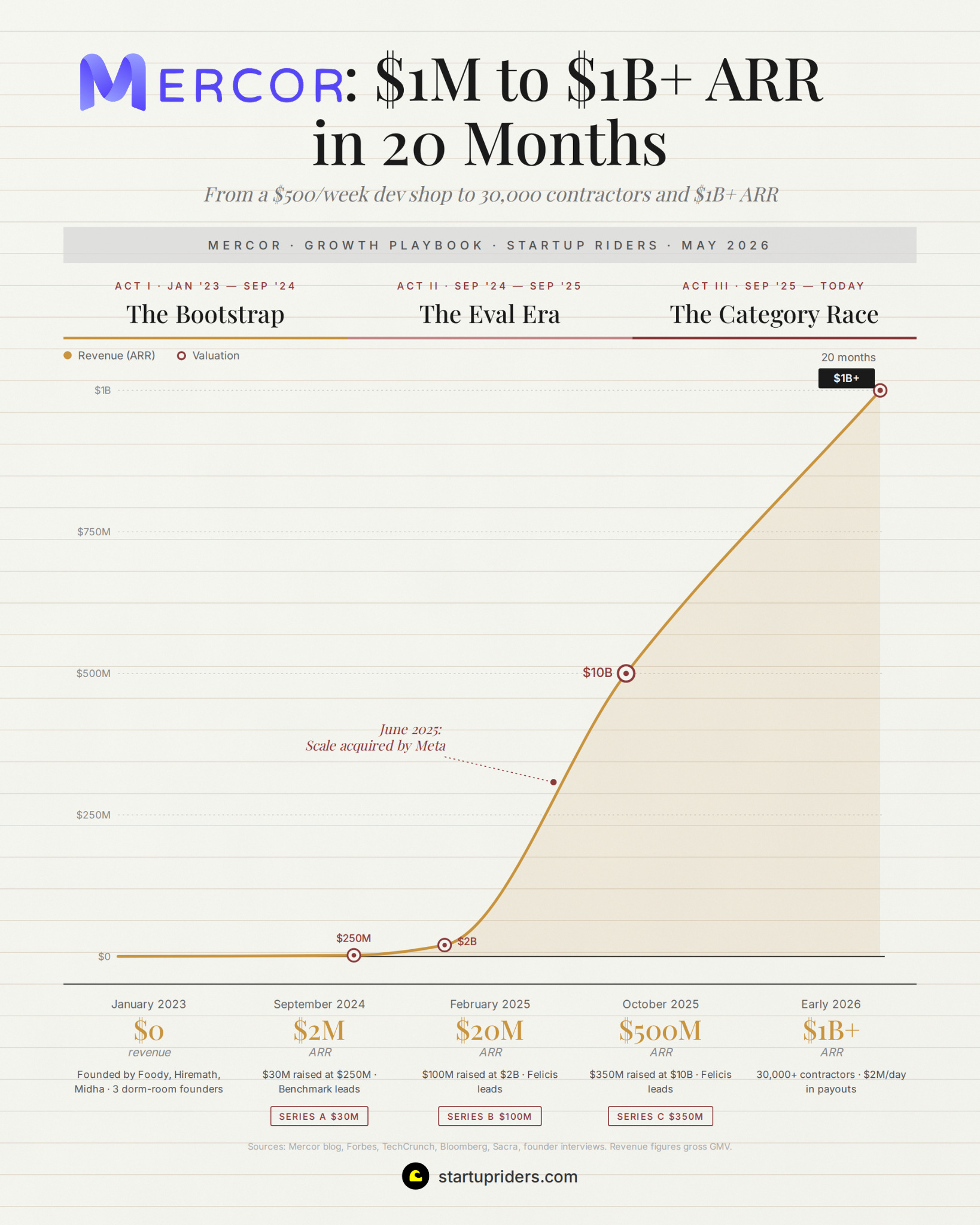
It’s been a wild year for Mercor. They crossed $1B in annualized revenue in early 2026, hit a $10B valuation at their Series C last October, and the 3 founders (22 years old at the time) became the youngest self-made billionaires in history.
Their ARR went from $1M → $1B+ in 20 months, and have been backed by our friends at Benchmark, Felicis and General Catalyst:
So I spent the past week pulling apart 14 founder interviews, every Mercor blog post, every funding round and every leaked detail about how they did it.
What you’ll learn
How Mercor charged before they raised
The matching engine that hires Indian devs and Goldman associates the same
Why paying supply 3x the going rate was a strategic move
How they turned Scale’s June 2025 collapse into 4x growth in two quarters
The benchmark trick that made every AI model launch an implicit Mercor ad
📐 Quick note on editorial and methodology: this report is me surfacing the 80/20 positive anomalies that explain their growth (not a comprehensive company profile). 14 founder interviews (Lenny’s Podcast, 20VC, No Priors, Stanford ETL, etc), plus reporting from TechCrunch, Bloomberg, Forbes, Wired, etc. All revenue figures sourced. Reported ARR figures throughout are gross GMV, assume 20-30% take rate. Treat directional estimates as directional.
From data labeling → agentic data
A little about the evolution of the market before we dive into the growth levers:
Where we come from
To understand the market we need to talk about Scale AI first, which was founded in 2016 by Alexandr Wang (MIT dropout who was 19 at the time).
The first product would route low-skill human labor to label training data for autonomous vehicle companies (i.e. workers drawing bounding boxes around stop signs, pedestrians, etc), and Waymo, Toyota, and GM were all early customers.
For 6 years that was the category where Scale, Surge, Appen, Sama, and a few others ran sort of a global call center for AI training data. The work was crowdsourced and the pay was around $30 an hour at the high end (often a lot less).
The bottleneck the labs cared about was volume because pre-training was the constraint that mattered and pre-training mostly needed bulk. And the category’s name became data labeling (profitable but commoditized). By 2022, Scale had raised over $600M at a $7.3B valuation.
Where we are
Two things shifted between late 2022 and mid-2024:
Pre-training stopped being the bottleneck: By 2023 the labs had crawled most of the public internet and the marginal return on more pre-training data was approaching 0, which moved the bottleneck to post-training (reinforcement learning, instruction tuning, expert-built evals, etc), which needs different labor (i.e. an undergrad cannot write a rubric for what a Goldman associate’s investment memo should look like).
The work itself changed: if the model is the product then the eval is the product requirement doc (PRD), and building the eval requires the same kind of person who’d write the PRD. So a $30/hour generalist typically can’t do it, you need a $200/hour FAANG engineer or a $500/hour M&A lawyer etc.
And it was our friends at Mercor who capitalised on this shift.
They started in January 2023 (before most of the market understood what was changing) and started paying 3x the going rate from day 1. They built a matching engine that worked for any role and sat in front of the right anchor customer at exactly the right moment.
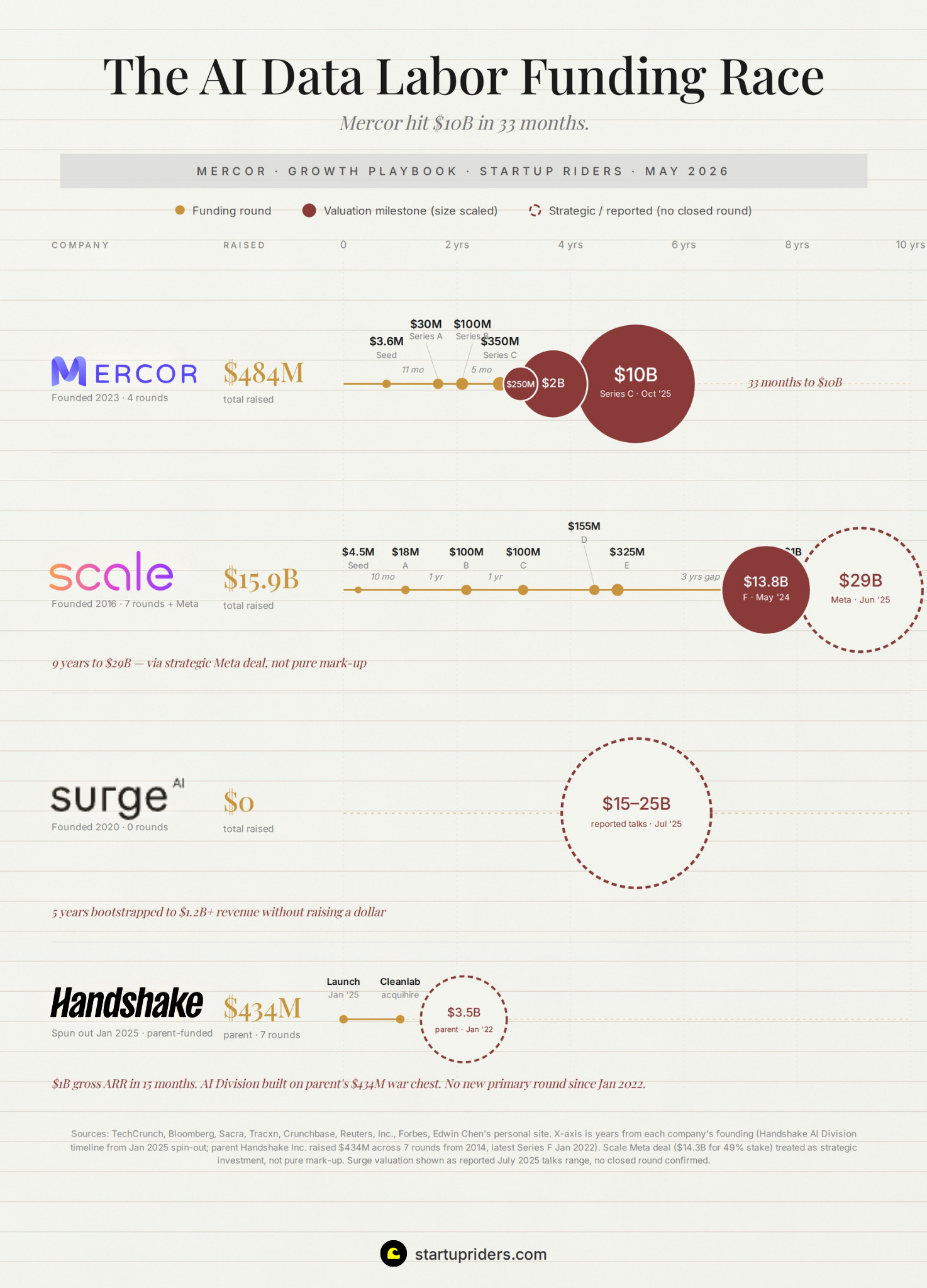
In June 2025, Meta acquired 49% of Scale for $14.3B. The founder left to run Meta’s superintelligence team and the category leader from the previous era got removed from the board in 90 days, while Mercor (along with Surge and Handshake) absorbed the demand.
The 4 companies on the chart represent the full competitive set right now, with Mercor’s curve being the steepest.
Where the market is going
Mercor’s founder says that soon every job will be taught to AI the way pilots learn in flight simulators (i.e. give it a task, let it try, score the attempt).
But the hard part is the scoring, because grading whether an AI did banking work right takes a real banker (which is what Mercor sells right now for banking, law, consulting, medicine, and engineering).
3 dynamics will shape the next 24 months.
The labs going in-house: xAI laid off 500 generalist annotators in September 2025 and shifted to internal teams, same with OpenAI that has apparently been quietly building in-house data operations. So the labs that can vertically integrate this layer eventually will, the question is whether they do it before Mercor builds enough expert supply and benchmark gravity to be too painful to displace.
The category consolidating: Handshake’s acquisition of Cleanlab in January 2026 and Taro in February 2026 is the first real M&A in this market and Mercor will likely follow. Let’s see what happens.
The work changing shape: The fear is this market shrinks once the models have learned everything but I don’t think it does, or at least not for a good while. The frontier keeps moving so the AI is always being graded against a harder task than last year. The world keeps changing (i.e. new laws, new jobs, new etc), so rubrics written today are stale in 2 years and as AI does more of the work, someone still has to verify it did the work right.
The TAM is hard to size cleanly because nobody knows how much labs will spend on training data when models are doing 10x or 100x the work humans do today, but it’s very, very big.
That’s the market in a nutshell, now to Mercor’s origin + growth levers:
Act 1: The Bootstrap
Jan 2023 → Sept 2024 · $0 → $2M ARR
Three high-school debate teammates start a recruiting company on January 1st, 2023. The original premise is to match American startups with Indian software engineers, charge $500 a week, and take 20%. They are 19 years old, running this out of a Palo Alto office that Surya Midha later described as “barely larger than a conference room.”
Nine months later they hit $1M in annualised revenue, still with no funding and no team beyond the 3 of them and a handful of engineers in India.
Growth Lever 1: They charged before they raised.
“I would hustle sending out contracts on PandaDoc to our friends, charging them $500 a week, taking 20 percent.”
They sold a paid service for 9 months before raising, which gave them leverage. By the time General Catalyst led the seed in late 2023, the matching engine was running and the unit economics were already mostly proven.
A lot of founders raise at the proof-of-concept stage when they still need the money to find out if the idea works (pre-seed / seed). Its especially impressive for Mercor to jump straight to seed with a good chunk of revenue considering their age and experience.
Not all business models allow for this, but in this case the leverage they got allows them to hit less dilution and most importantly a cap table they could hand-pick (Thiel, Dorsey, D’Angelo, and Summers all got in early).
It also bought them a position most startups never get which is that by Series C the business was profitable enough that Foody could say “we don’t really need to go out for financing” (20VC, September 2025). And apparently every round since has been an offer they didn’t need rather than one they had to chase.
Growth Lever 2: They built one engine that worked for every role.
“A huge part of the Mercor platform is actually not building specifically for any of these roles but instead building technology that generalises really really well.”
The obvious play in a hiring marketplace is to specialise (i.e. one vertical for engineers, one for lawyers, one for doctors etc). The verticalisation plays well in pitch decks because it’s specific and defensible.
But these guys went the other way.
The matching engine they built in 2023 to hire Indian software engineers at $500 a week is the same one that hires Goldman associates at $500 an hour today. They have the same intake (resume + portfolio + GitHub crawl), same AI interviewer (custom 20-minute conversation, spun up in under 10 seconds for any role) and same matching model underneath:
“Whenever the models improve, the experience for applicants on our platform also improves pretty significantly. Can we ride that wave to make our product better and better and better.”
This is the lever that scaled supply from roughly 2,000 contractors in early 2024 to 30,000+ today without a corresponding ops headcount blowup. Scale and Surge built workforce ops infrastructure for one type of labor while Mercor built infrastructure that absorbs new labor types as a feature.
The product compounding is multi-directional because each new role on the platform improves matching for adjacent roles (a lawyer’s interview rubric teaches the engine something about how to interview an investment banker).
And each lab Mercor works with feeds back signal on which experts actually drive model improvement. So the matching engine keeps learning even when the supply mix and customer mix change.
Growth Lever 3: They got one lab deep instead of ten labs shallow.
“I was 20 years old at the time, so I was nervous about whether I’d have to use my fake ID. But fortunately, we just got deviled eggs, and we shared this vision.”
In mid-2023 a customer introduced Mercor to the xAI co-founding team and 2 days later the trio (still college students btw) meets the xAI team at the Tesla office. xAI wasn’t ready for human data yet, but the meeting told Foody the market was about to shift.
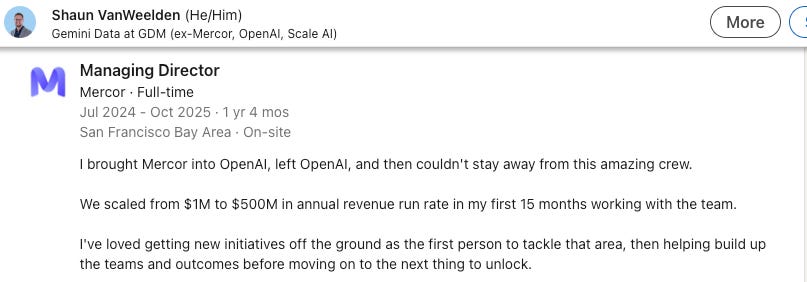
A few months later, after spamming OpenAI’s head of human data operations with emails (never underestimate the power of cold outbound) Foody landed a meeting with Shaun VanWeelden.
OpenAI wanted Mercor to find Math Olympiad winners to help train OpenAI’s models and within 9 months Mercor was OpenAI’s largest data vendor.
What’s interesting here is that they apparently didn’t chase 10 frontier labs at once but decided to get one lab deep, and that one relationship opened every other door.
Going deep on OpenAI also dragged product quality up. Foody calls Mercor “a deep research partner to our customers.” Serving OpenAI meant building for the hardest customer first with investment-grade rubrics, FAANG-level talent vetting, latency tight enough for hourly delivery and so on. So once they could serve OpenAI every other lab was a downgrade in difficulty.
That anchor relationship is also why Mercor was positioned to win when the category leader stumbled a year later:
Act 2: The Eval Era
Sept 2024 → Sept 2025 · $2M → $500M ARR
They then went on to grow 54% month-over-month, sustained, for 12 months.
Most companies that scale at that rate either burn cash to do it (Uber, DoorDash) or hire furiously to keep up (Scale itself did this from 2019-2022).
But Mercor managed to scale supply without scaling ops and keeping the business profitable. The 3 levers in this act are how: